

今天分享一个粉丝在美团二面遇到的问题——如何设计一个百万人抽奖系统?
思维导图
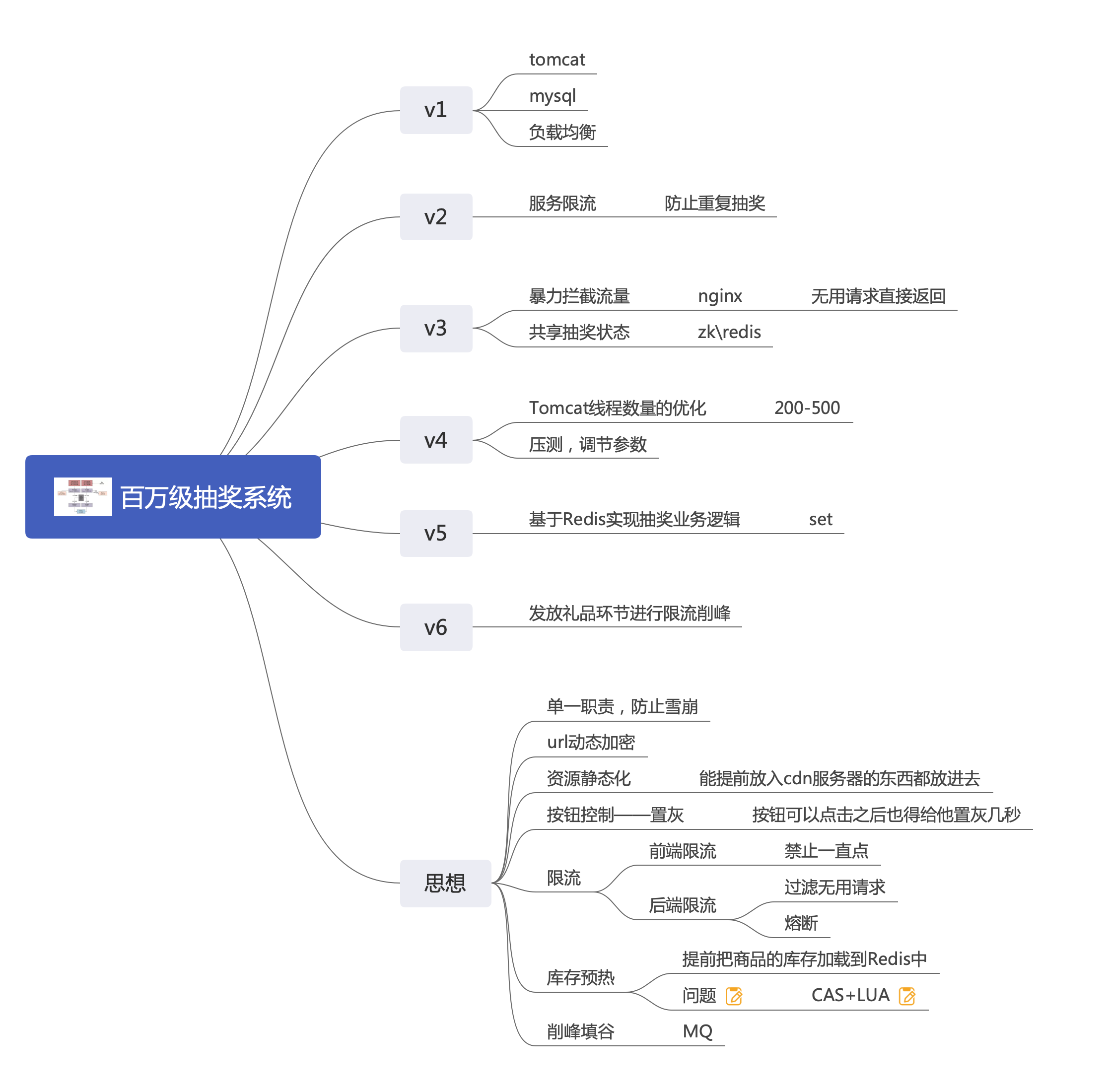
导图按照由浅入深的方式进行讲解,架构从来不是设计出来的,而是演进而来的
从一个几百人的抽奖系统到几万人,再到百万人,不断增加新的东西。
最后总结归纳一套设计思想,也是万能模板,这样面试官问任何高并发系统,只需从这几个方向去考虑就可以了。
V0——单体架构
如果现在让你实现几十人的抽奖系统,简单死了吧,直接重拳出击!
两猫一豚走江湖,中奖入库,调通知服务,查库通知,完美!
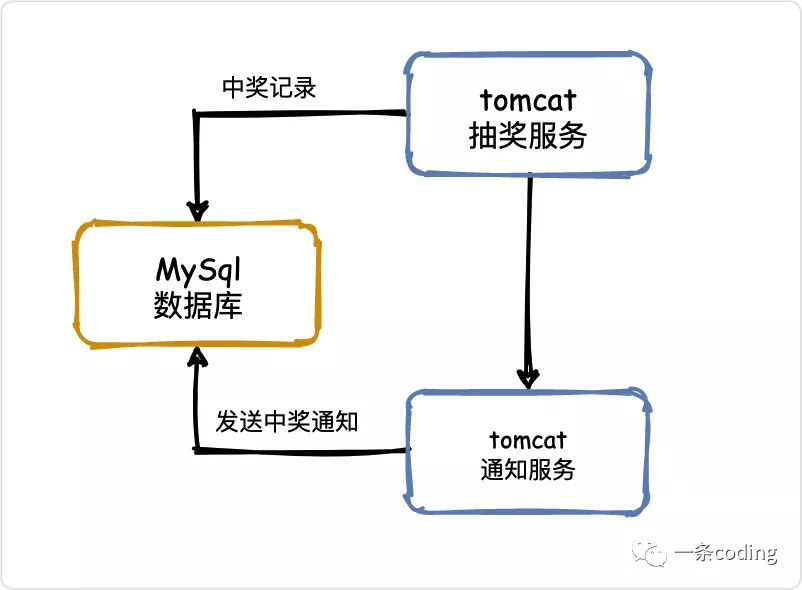
相信大家学java时可能都做过这种案例,思考🤔一下存在什么问题?
-
单体服务,一着不慎满盘皆输 -
抽了再抽,一个人就是一支军队 -
恶意脚本,没有程序员中不了的奖
接下来就聊聊怎么解决这些问题?
V1——负载均衡
当一台服务器的单位时间内的访问量越大时,服务器压力就越大,大到超过自身承受能力时,服务器就会崩溃。
为了避免服务器崩溃,让用户有更好的体验,我们通过负载均衡的方式来分担服务器压力。
负载均衡就是建立很多很多服务器,组成一个服务器集群,当用户访问网站时,先访问一个中间服务器,好比管家,由他在服务器集群中选择一个压力较小的服务器,然后将该访问请求引入该服务器。
如此以来,用户的每次访问,都会保证服务器集群中的每个服务器压力趋于平衡,分担了服务器压力,避免了服务器崩溃的情况。
负载均衡是用「反向代理」的原理实现的。具体负载均衡算法及其实现方式我们下文再续。
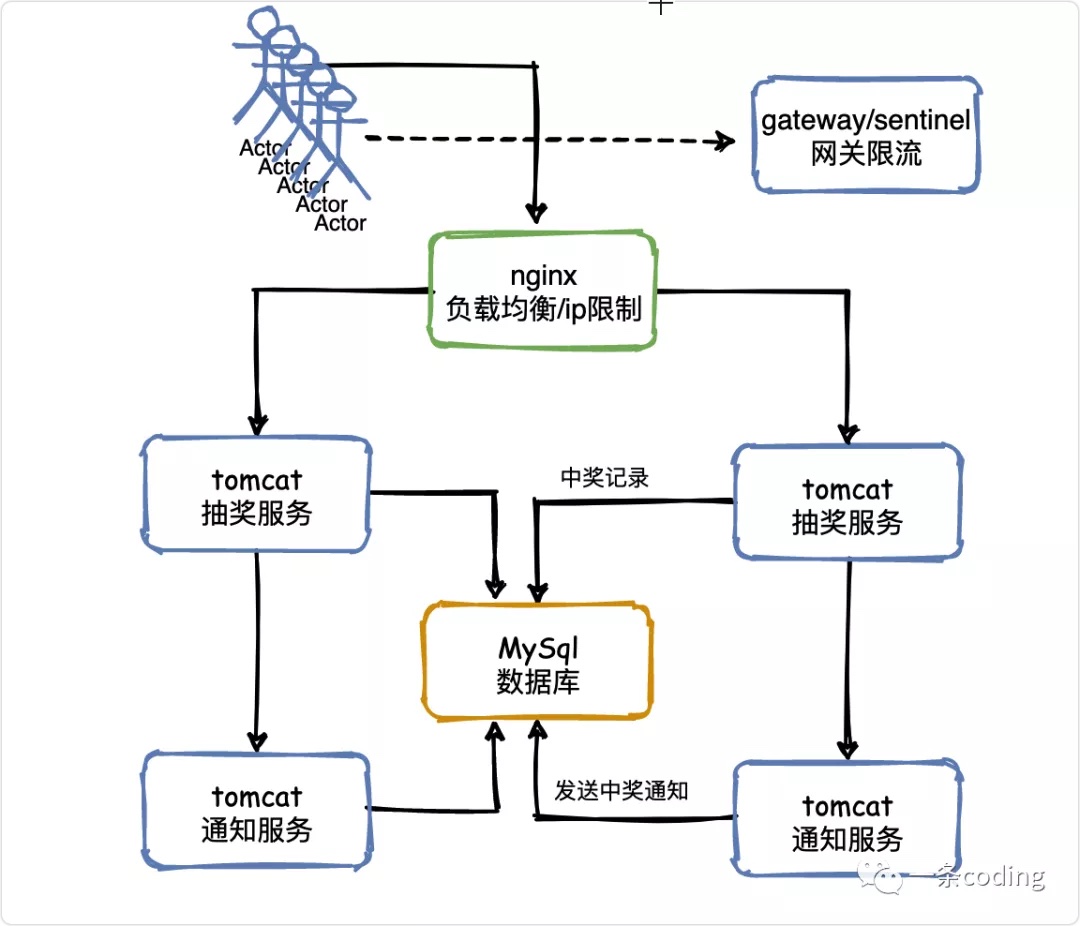
负载均衡虽然解决了单体架构一着不慎满盘皆输的问题,但服务器成本依然不能保护系统周全,我们必须想好一旦服务器宕机,如何保证用户的体验。
即如何缓解开奖一瞬间时的大量请求。
V2——服务限流
限流主要的作用是保护服务节点或者集群后面的数据节点,防止瞬时流量过大使服务和数据崩溃(如前端缓存大量实效),造成不可用。
还可用于平滑请求。
在上一小节我们做好了负载均衡来保证集群的可用性,但公司需要需要考虑服务器的成本,不可能无限制的增加服务器数量,一般会经过计算保证日常的使用没问题。
限流的意义就在于我们无法预测未知流量,比如刚提到的抽奖可能遇到的:
-
重复抽奖 -
恶意脚本
其他一些场景:
-
热点事件(微博) -
大量爬虫
这些情况都是无法预知的,不知道什么时候会有10倍甚至20倍的流量打进来,如果真碰上这种情况,扩容是根本来不及的(弹性扩容都是虚谈,一秒钟你给我扩一下试试)
明确了限流的意义,我们再来看看如何实现限流
防止用户重复抽奖
重复抽奖和恶意脚本可以归在一起,同时几十万的用户可能发出几百万的请求。
如果同一个用户在1分钟之内多次发送请求来进行抽奖,就认为是恶意重复抽奖或者是脚本在刷奖,这种流量是不应该再继续往下请求的,在负载均衡层给直接屏蔽掉。
可以通过nginx配置ip的访问频率,或者在在网关层结合sentinel配置限流策略。
用户的抽奖状态可以通过redis来存储,后面会说。
拦截无效流量
无论是抽奖还是秒杀,奖品和商品都是有限的,所以后面涌入的大量请求其实都是无用的。
举个例子,假设50万人抽奖,就准备了100台手机,那么50万请求瞬间涌入,其实前500个请求就把手机抢完了,后续的几十万请求就没必要让他再执行业务逻辑,直接暴力拦截返回抽奖结束就可以了。
同时前端在按钮置灰上也可以做一些文章。
那么思考一下如何才能知道奖品抽完了呢,也就是库存和订单之前的数据同步问题。
服务降级和服务熔断
有了以上措施就万无一失了吗,不可能的。所以在服务端还有降级和熔断机制。
在此简单做个补充,详细内容请持续关注作者。
有好多人容易混淆这两个概念,通过一个小例子让大家明白:
假设现在一条粉丝数突破100万,冲上微博热搜,粉丝甲和粉丝乙都打开微博观看,但甲看到了一条新闻发布会的内容,乙却看到”系统繁忙“,过了一会,乙也能看到内容了。
(请允许一条幻想一下😎)
在上述过程中,首先是热点时间造成大量请求,发生了服务熔断,为了保证整个系统可用,牺牲了部分用户乙,乙看到的”系统繁忙“就是服务降级(fallback),过了一会又恢复访问,这也是熔断器的一个特性(hystrix)
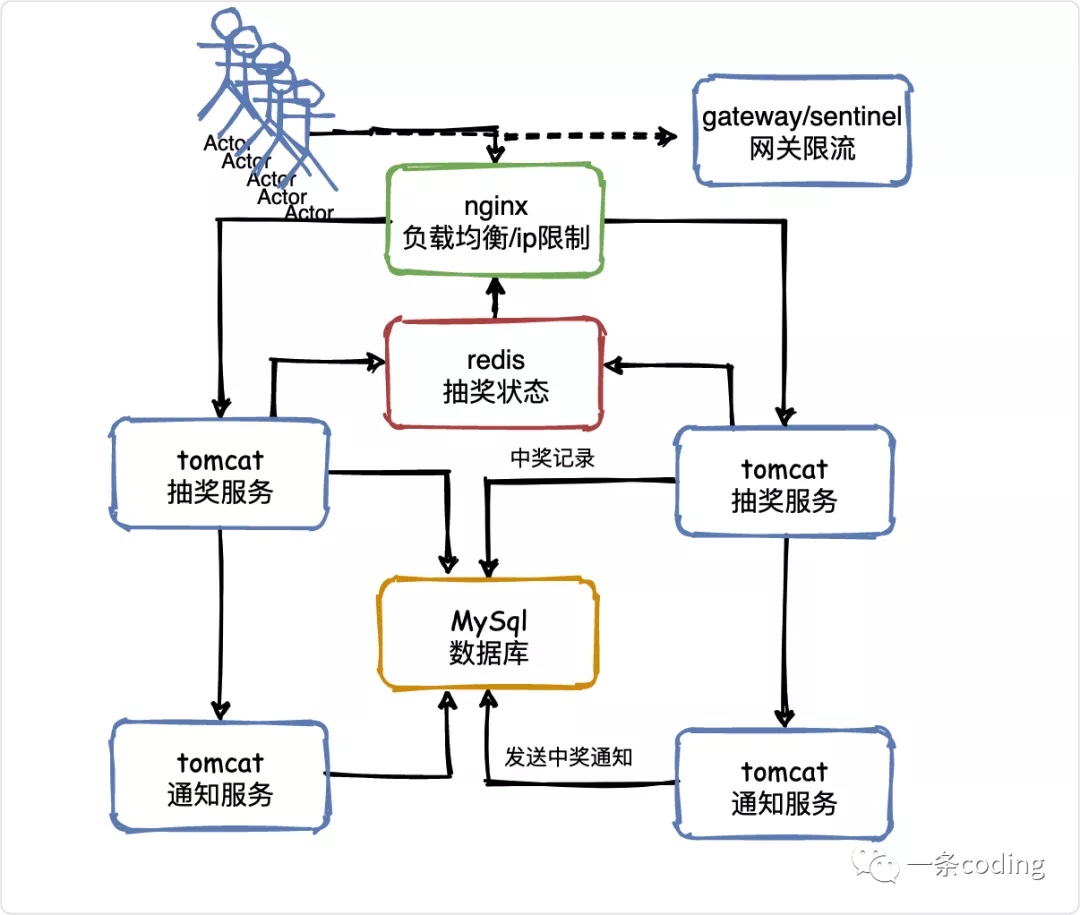
V3 同步状态
接着回到上一节的问题,如何同步抽奖状态?
这不得不提到redis,被广泛用于高并发系统的缓存数据库。
我们可以基于Redis来实现这种共享抽奖状态,它非常轻量级,很适合两个层次的系统的共享访问。
当然其实用ZooKeeper也是可以的,在负载均衡层可以基于zk客户端监听某个znode节点状态。一旦抽奖结束,抽奖服务更新zk状态,负载均衡层会感知到。
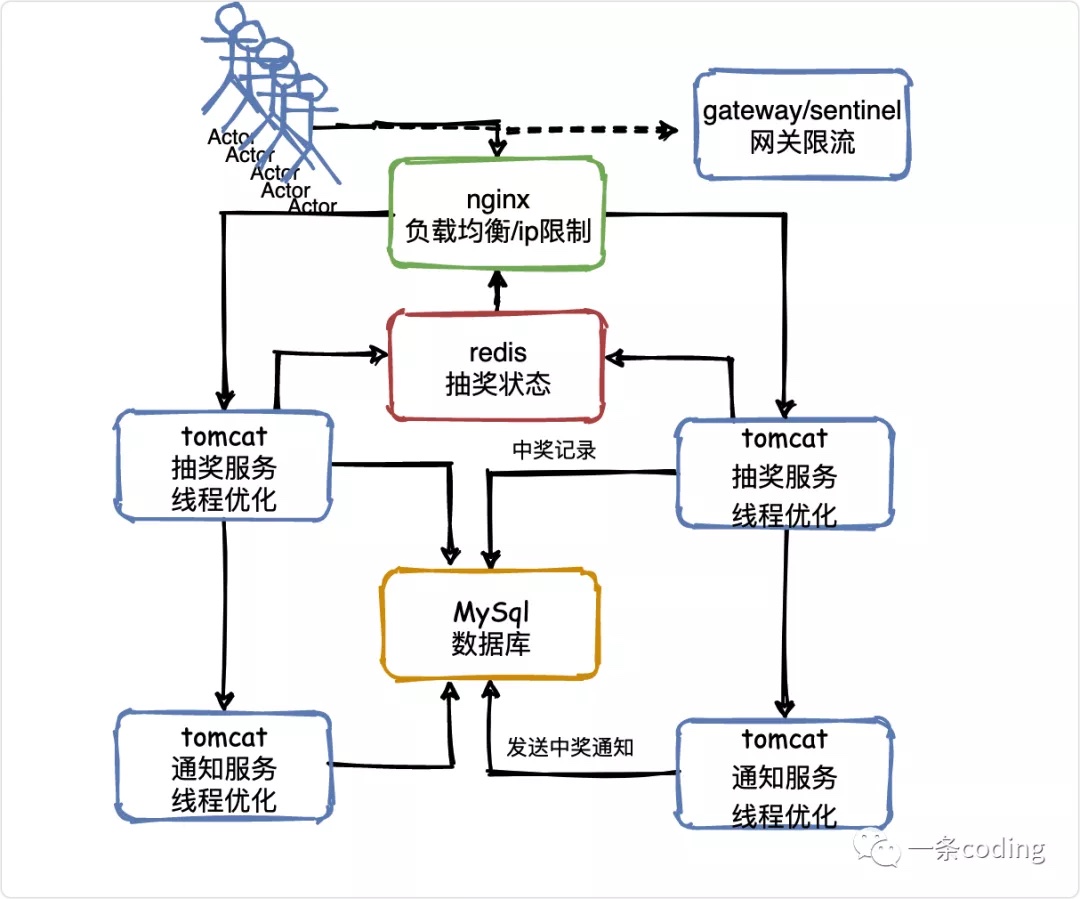
V4线程优化
对于线上环境,工作线程数量是一个至关重要的参数,需要根据自己的情况调节。
众所周知,对于进入Tomcat的每个请求,其实都会交给一个独立的工作线程来进行处理,那么Tomcat有多少线程,就决定了并发请求处理的能力。
但是这个线程数量是需要经过压测来进行判断的,因为每个线程都会处理一个请求,这个请求又需要访问数据库之类的外部系统,所以不是每个系统的参数都可以一样的,需要自己对系统进行压测。
但是给一个经验值的话,Tomcat的线程数量不宜过多。因为线程过多,普通服务器的CPU是扛不住的,反而会导致机器CPU负载过高,最终崩溃。
同时,Tomcat的线程数量也不宜太少,因为如果就100个线程,那么会导致无法充分利用Tomcat的线程资源和机器的CPU资源。
所以一般来说,Tomcat线程数量在200~500之间都是可以的,但是具体多少需要自己压测一下,不断的调节参数,看具体的CPU负载以及线程执行请求的一个效率。
在CPU负载尚可,以及请求执行性能正常的情况下,尽可能提高一些线程数量。
但是如果到一个临界值,发现机器负载过高,而且线程处理请求的速度开始下降,说明这台机扛不住这么多线程并发执行处理请求了,此时就不能继续上调线程数量了。
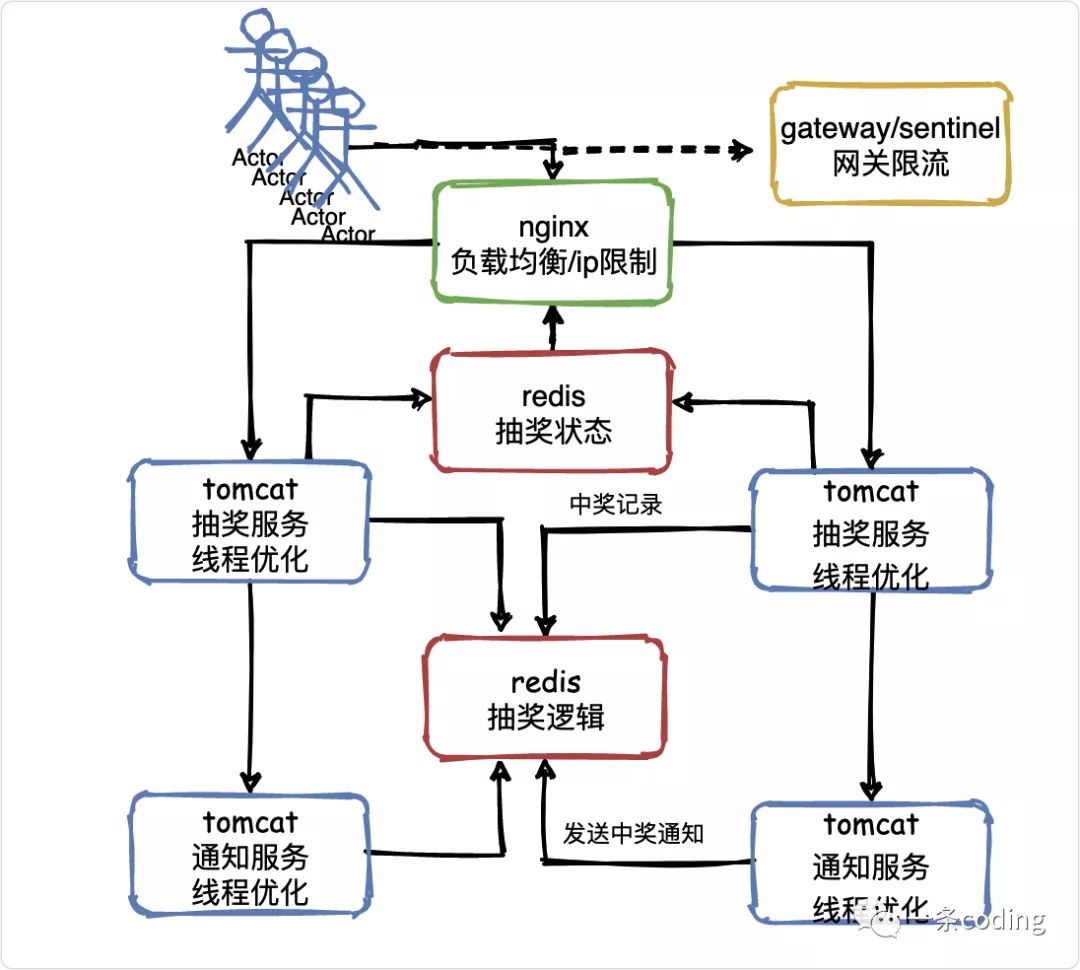
V5业务逻辑
抽奖逻辑怎么做?
好了,现在该研究一下怎么做抽奖了
在负载均衡那个层面,已经把比如50万流量中的48万都拦截掉了,但是可能还是会有2万流量进入抽奖服务。
因为抽奖活动都是临时服务,可以阿里云租一堆机器,也不是很贵,tomcat优化完了,服务器的问题也解决了,还剩啥呢?
Mysql,是的,你的Mysql能抗住2万的并发请求吗?
答案是很难,怎么办呢?
把Mysql给替换成redis,单机抗2万并发那是很轻松的一件事情。
而且redis的一种数据结构set很适合做抽奖,可以随机选择一个元素并剔除。
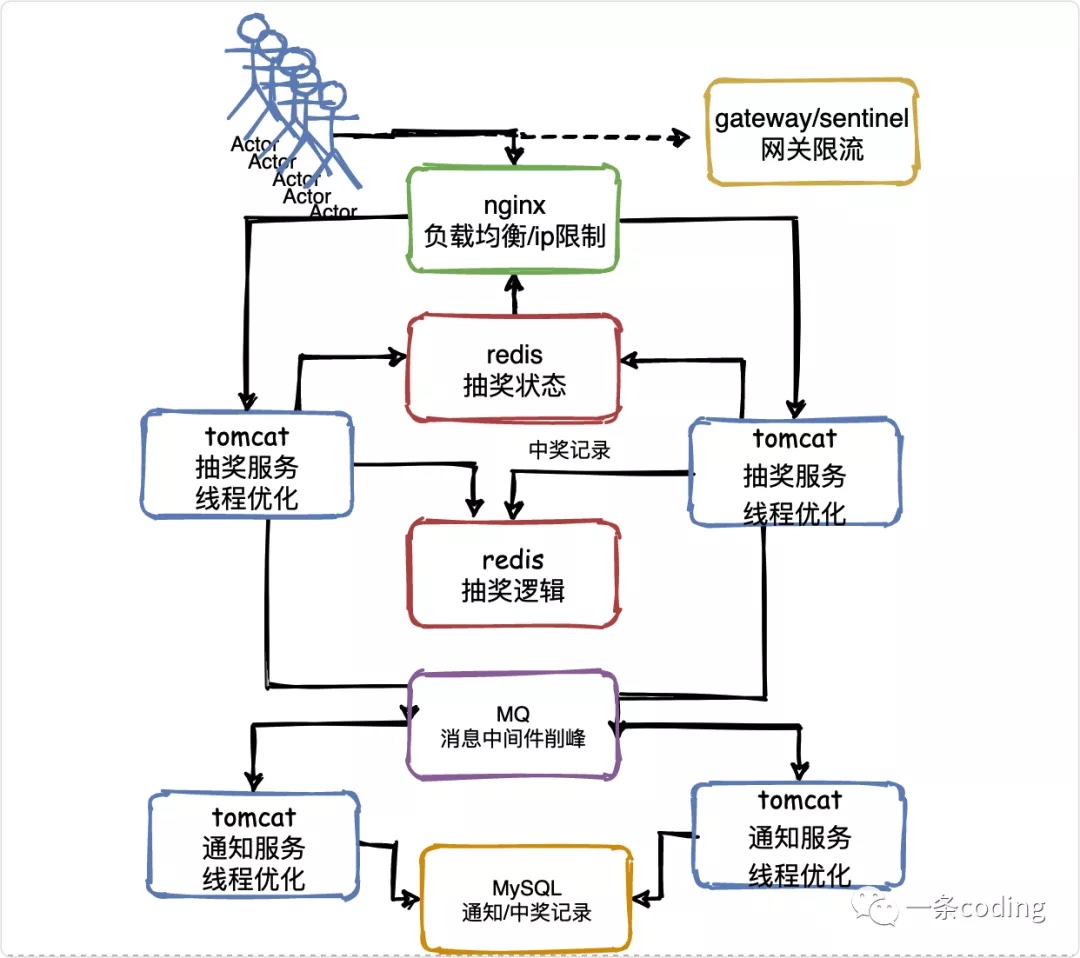
V6流量削峰
由上至下,还剩中奖通知部分没有优化。
思考这个问题:假设抽奖服务在2万请求中有1万请求抽中了奖品,那么势必会造成抽奖服务对礼品服务调用1万次。
那也要和抽奖服务同样处理吗?
其实并不用,因为发送通知不要求及时性,完全可以让一万个请求慢慢发送,这时就要用到消息中间件,进行限流削峰。
也就是说,抽奖服务把中奖信息发送到MQ,然后通知服务慢慢的从MQ中消费中奖消息,最终完成完礼品的发放,这也是我们会延迟一些收到中奖信息或者物流信息的原因。
假设两个通知服务实例每秒可以完成100个通知的发送,那么1万条消息也就是延迟100秒发放完毕罢了。
同样对MySQL的压力也会降低,那么数据库层面也是可以抗住的。
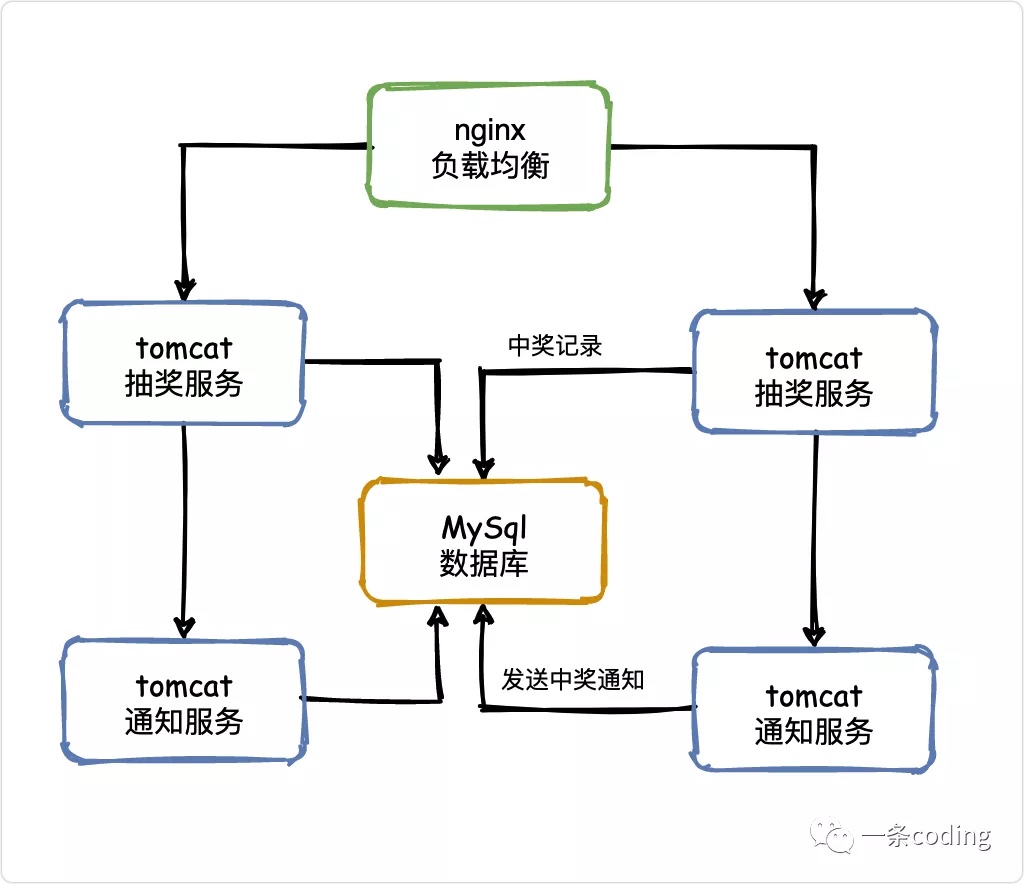
看一下最终结构图:
答题模板
所谓答题模板,就是高并发问题的几个思考方向和解决方案。
单一职责
一个基本的设计思想,回想高中物理的串联和并联,串联一灭全灭,并联各自有一个通路。
一样的道理,高内聚,低耦合。
微服务之所以兴起就是因为把复杂的功能进行拆分,即使网站崩了,无法下单,但是浏览功能依然健康,而不是所有服务引起连锁反应,像雪崩一样,全面瘫痪。
URL动态加密
这说的是防止恶意访问,有些爬虫或者刷量脚本会造成大量的请求访问你的接口,你更加不知道他会传什么参数给你,所以我们定义接口时一定要多加验证,因为不止是你的朋友调你的接口,敌人也有可能。
静态资源——CDN
CDN全称内容分发网络,是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。
通俗的讲,就是把经常访问又费时的资源放在你附近的服务器上。
淘宝的图片访问,有98%的流量都走了CDN缓存。只有2%会回源到源站,节省了大量的服务器资源。
但是,如果在用户访问高峰期,图片内容大批量发生变化,大量用户的访问就会穿透cdn,对源站造成巨大的压力。
所以,对于图片这种静态资源,尽可能都放入CDN。
服务限流
在上面已有讲解,可分为前端限流和后端限流。
-
前端:按钮禁用,ip黑名单 -
后端:服务熔断,服务降级,权限验证
数据预热
可以采用定时任务(elastic-job)实时查询Druid,把热点数据放入redis缓存中。
思考一个问题:
比如现在库存只剩下1个了,我们高并发嘛,4个服务器一起查询了发现都是还有1个,那大家都觉得是自己抢到了,就都去扣库存,那结果就变成了-3,是的只有一个是真的抢到了,别的都是超卖的。咋办?
回答:
可以用CAS+LUA脚本实现。
Lua脚本是类似Redis事务,有一定的原子性,不会被其他命令插队,可以完成一些Redis事务性的操作。这点是关键。
写一个脚本把判断库存扣减库存的操作都写在一个脚本丢给Redis去做,那到0了后面的都Return False了是吧,一个失败了你修改一个开关,直接挡住所有的请求。
削峰填谷
精通一个中间件会给你加分很多
消息队列已经逐渐成为企业IT系统内部通信的核心手段。
它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。
当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、RabbitMQ,炙手可热的Kafka,阿里巴巴自主开发RocketMQ等。
最原始的MQ,生产者先将消息投递一个叫做「队列」的容器中,然后再从这个容器中取出消息,最后再转发给消费者,仅此而已。

