

在字节跳动的终面中,居然遇到这个题目,好亲切。题目如下:
A文件有32亿个url链接,B文件有64亿个url链接,求A和B中的公共url链接。

一. 初步思考
一些朋友可能觉得,这个问题很简单啊,把A文件和B文件同时加载到内存中,然后进行循环查找比较,貌似万事大吉。
为了便于理解原问题,我用图解的方式来进行。设A文件有5个美女,居于上面一行;B文件有5个美女,居于下面一行。
那么,怎么找出上下两行的公共部分呢?且看最直观的思路,那就一个个地找呗。
第1步:
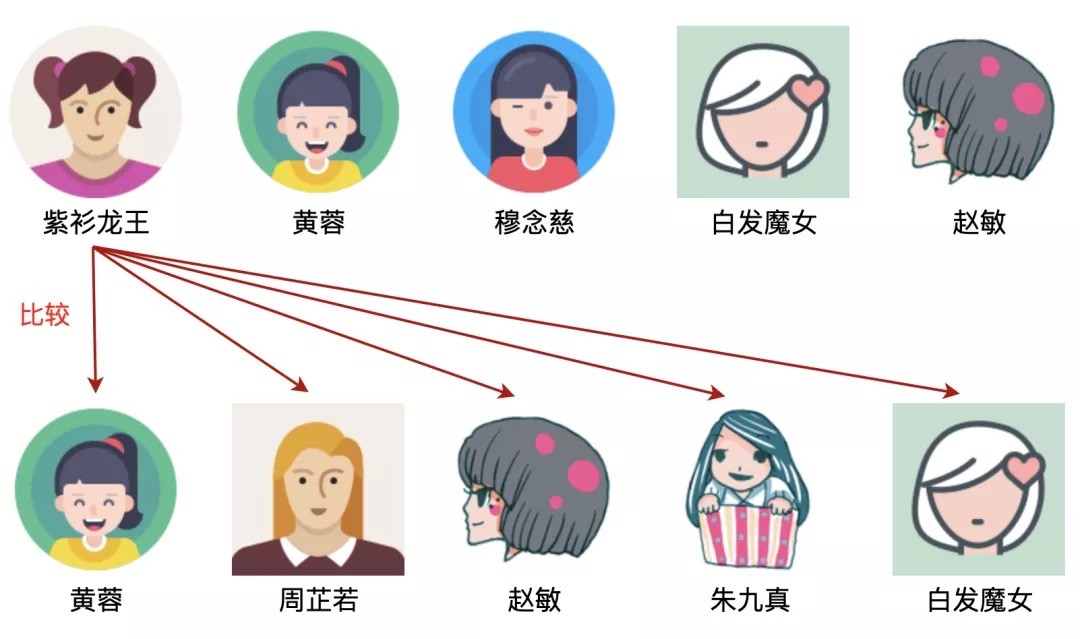
以紫衫龙王为例,发现下面一行没有紫衫龙王,所以紫衫龙王不是上下的公共部分,如图:
第2步:
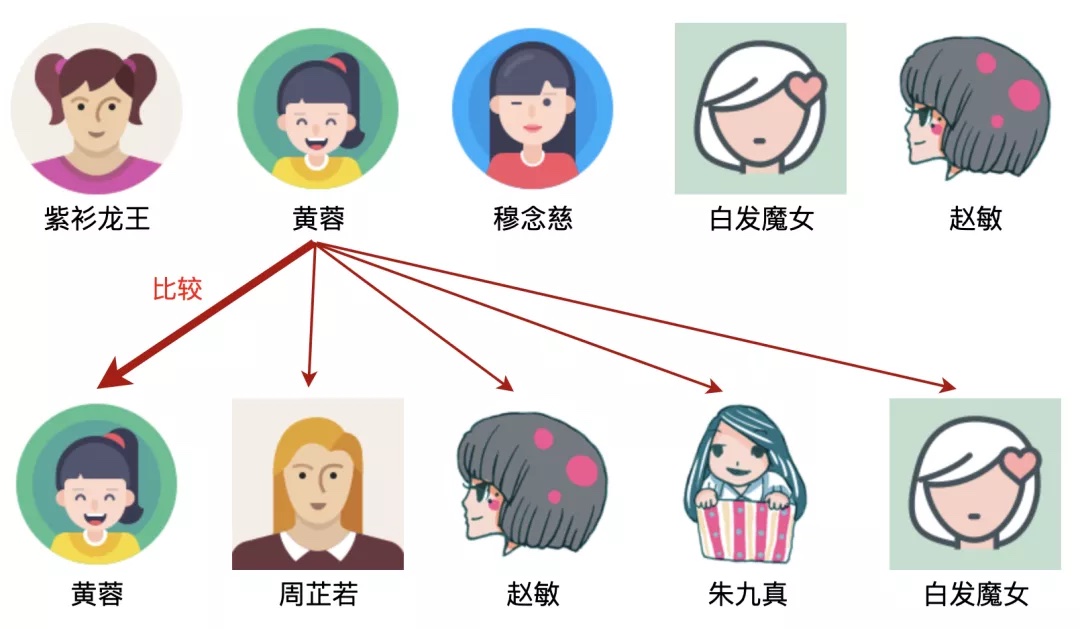
以黄蓉为例,发现下面一行有黄蓉,所以黄蓉是上下的公共部分,如图:
第3步:
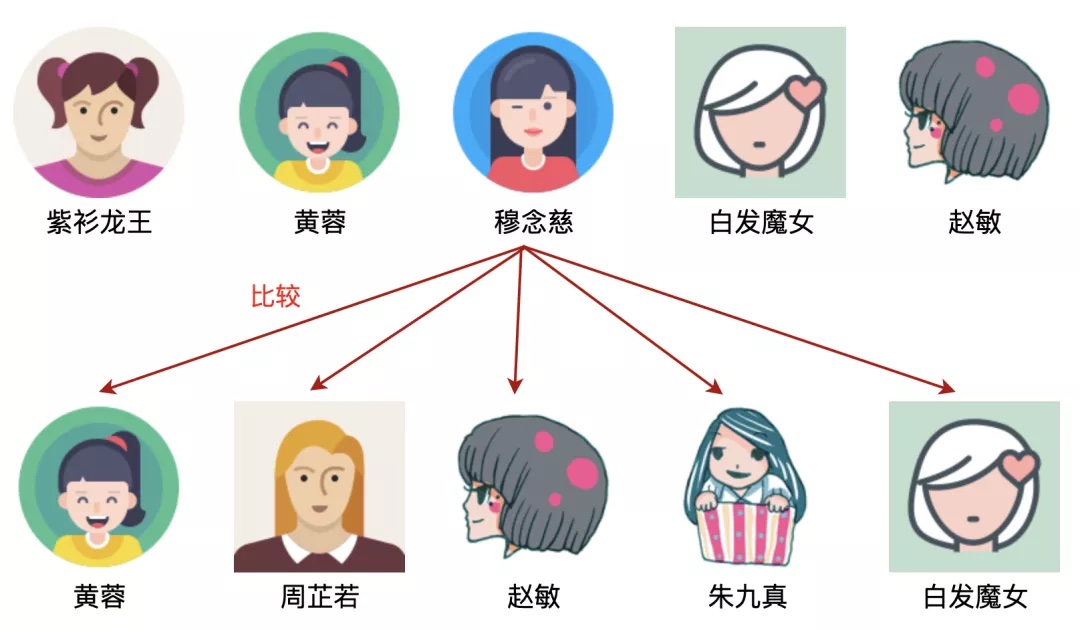
以穆念慈为例,发现下面一行没有穆念慈,所以穆念慈不是上下的公共部分,如图:
第4步:
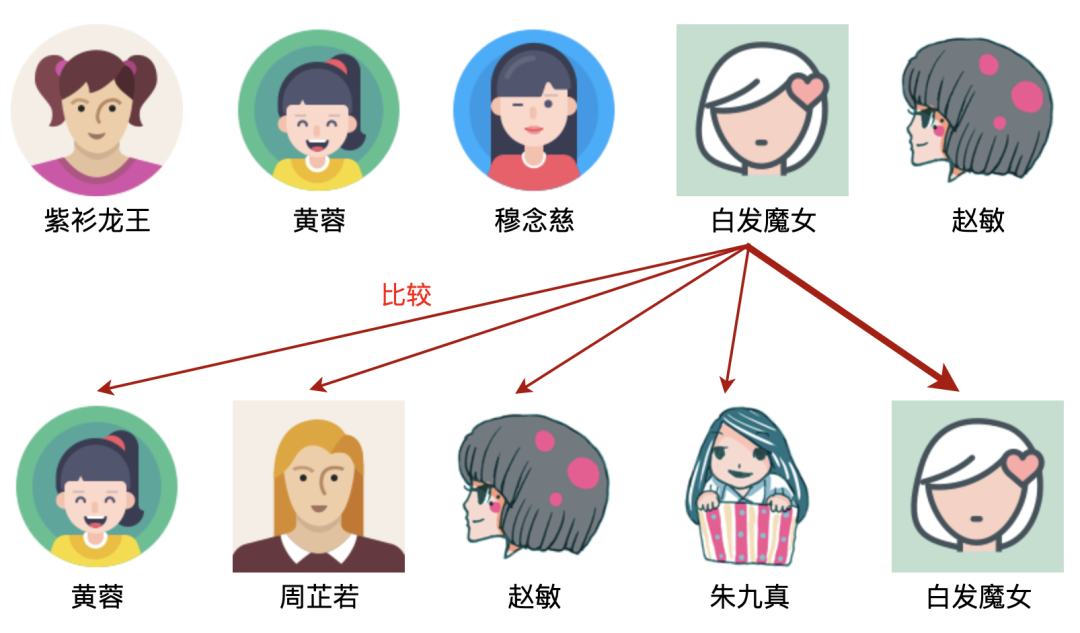
以白发魔女为例,发现下面一行有白发魔女,所以白发魔女是上下的公共部分,如图:
第5步:
以赵敏为例,发现下面一行有赵敏,所以赵敏是上下的公共部分,如图:

我们看到,整个过程进行了25次比较。显然,上下两行的公共部分是:黄蓉、赵敏、白发魔女。
如果A有m个元素,B有n个元素,则时间复杂度为O(m*n),显然,无法通过字节跳动的面试。
二. 进阶思考
从时间复杂度上来讲,上面的方法肯定不是最优的,这里的问题在哪里呢?问题还是出在查找的思路上。
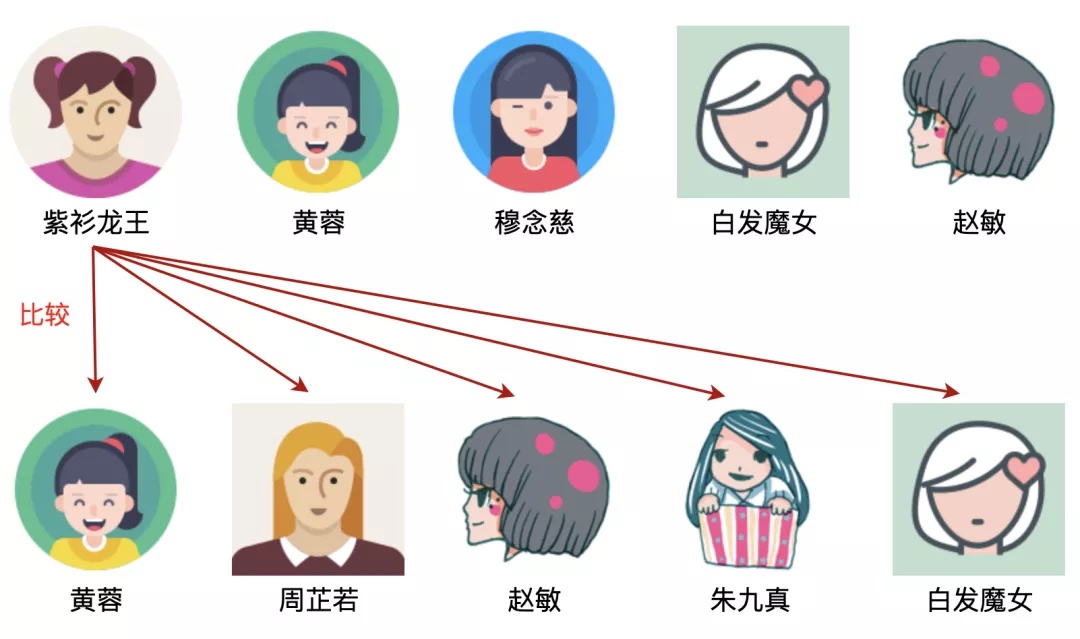
我们以紫衫龙王的查找为例,使用遍历查找的思路是很糟糕的。从下图可以看出,需要查找5次才有结果:
回顾一下查找算法,比遍历查找更快的是二分查找,比二分查找更快的是哈希查找。
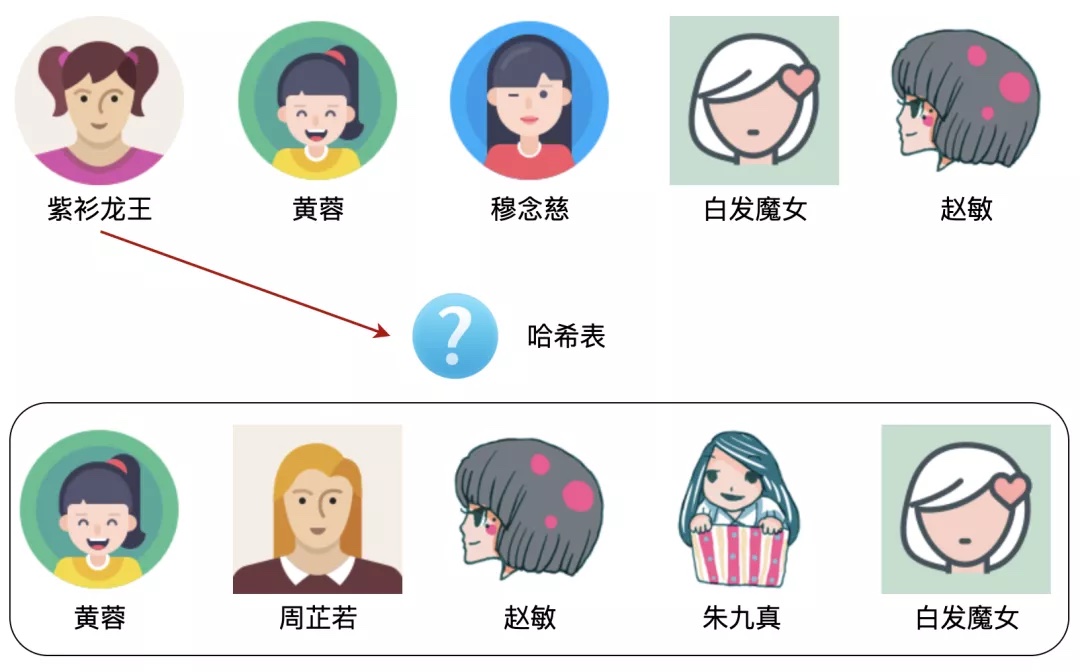
来看看使用哈希表进行查找的图示,哈希查找的时间复杂度为O(1),不需要比较5次:
貌似万事大吉了,但依然无法通过字节跳动的面试,这又是为什么呢?猫腻在哪里?
醒醒,快醒醒,这明显是一道海量数据问题,内存容纳不下,所以必须想其他的方法。
三. 终极思考
由于是海量数据问题,内存容纳不下,那怎么办呢?可以考虑使用分治的思想,说白了,就是大问题化小,小问题化了。
还是以上述的美女为例,我们可以考虑对这些美女进行分类。具体的分类标准有很多,比如,可以考虑以名字长度来分。
原来的图示如下:
根据名字长度划分后图示如下:

显而易见,这就实现了化大为小,在化大为小之后,内存足够容纳得下,不用担心了。
很容易发现,上下两行的公共部分分别是:黄蓉、赵敏、白发魔女。问题得到解决啦。
值得注意的是,我们以名字长度为4的房间为例,针对紫衫龙王,仍选择用哈希查找。
四. 破解原题
我们一起来回顾下原题:
A文件有32亿个url链接,B文件有64亿个url链接,求A和B中的公共url链接。
显然,内存容纳不下这么多数据,因此需要采用分割的方法对A和B两个文件中的url进行分类。
怎么分类呢?我们当然可以根据url的长度进行分类,分成不同的比较组,比如:
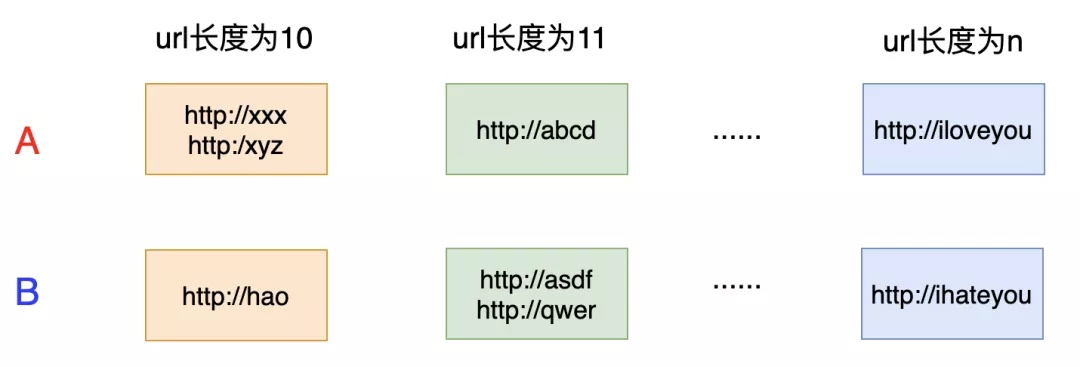
这样就能解决问题了。但是,还有一个问题,这种划分合理吗?是否存在某个长度的url有很多呢?
会的,一定会的。如果某个长度的url很多,会导致小文件也很大,导致内存容纳不下,那怎么办?
可以考虑采取哈希的思想,具体来说就是对每个url求md5值,然后按照md5值的首字母来分割:

把大文件按照一定的规则切割成小文件后,内存容纳不下的问题解决了。按照上述分法之后,如果文件还是太大,那怎么办呢?
很简单,可以考虑多分割一些,比如按照md5后的前两个字母来分割。显然,一个大文件可以分为256个小文件,如下所示:
| 文件分割 | md5后前两个字母 |
| 小文件1 | aa |
| 小文件2 | ab |
| 小文件3 | ac |
| 小文件4 | ad |
| … | … |
| 小文件256 | zz |
总之,核心思想是:
-
哈希分治,把大文件切割为很多的小文件
-
在每一组小文件中,找出它们的共同url
表格示意图如下:
| md5后前两个字母 | A |
VS | B |
| aa | A1文件 | VS | B1文件 |
| ab | A2文件 | VS | B2文件 |
| ac | A3文件 | VS | B3文件 |
| ad | A4文件 | VS | B4文件 |
| … | … | VS | … |
| zz | A256文件 | VS | B256文件 |

😊😊😊