

DFA:Deterministic Finite Automaton,也就是确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。
这个描述有点难懂,我用一段白话来说明一下:你有一个集合,集合内的每一个元素都标明了自己的状态,通过你已知的某些事件,你可以从当前元素的状态得到下一个状态,从而知道下一个元素是啥,即event + state = next state。而且毕竟集合是有限的,一定能从一个节点找到最终的节点。
举个例子
现在有几个关键词:妙蛙种子,妙蛙草,妙蛙花,皮卡丘,皮丘。我们现在对这些关键词进行一些操作,构造出一个有穷自动机出来。
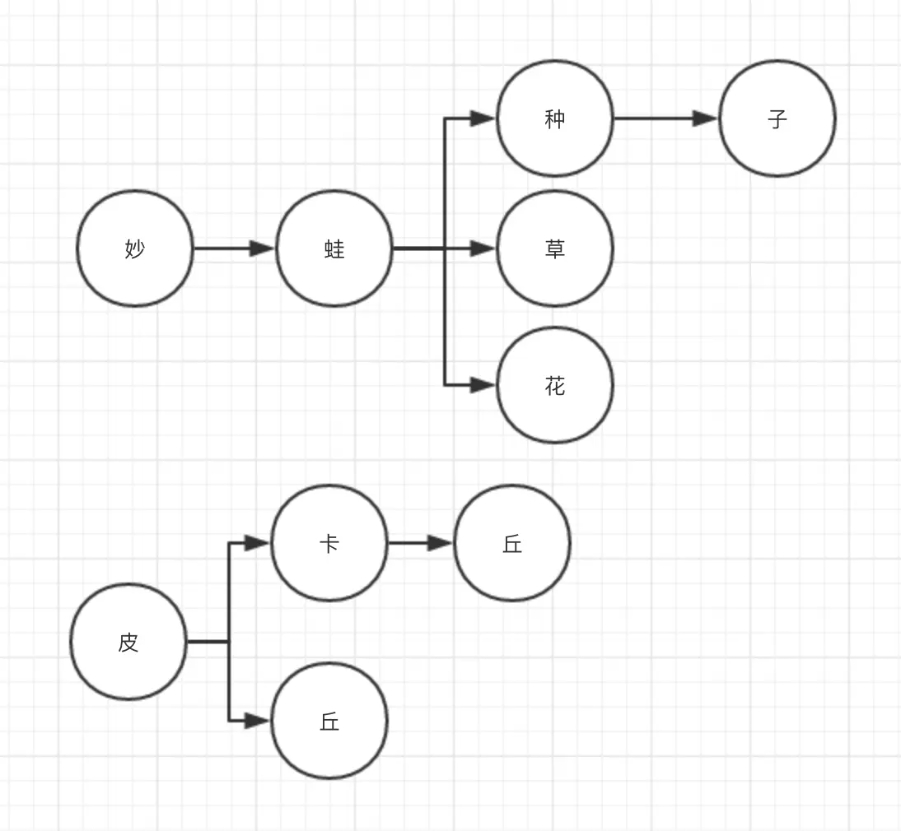
如果我们将这些词整理成这样一个树状结构,我们就可以根据第一个字,去对他所属的树去进行检索,这将大大提高搜索的效率。
以妙蛙花为例:
- 先通过“妙”字去搜索,看看存不存在以“妙”为根节点的树。若不存在,则这个词不在我们的关键词中。
- 若存在这个树,则我们去匹配第二个字“蛙”,看看这个字是不是在当前这个树的第二个节点上。若不存在话,则这个词不在我们的关键词中。然后依次类推下去。
- 如何判断这棵树已经到最末尾了,即到了关键字最后一个字。我们在生成这颗树的时候,给最后的节点加上一个属性(isEnd=true),标明这个关键词已经结束了。
下面给出这个自动机的HashSet实例:
妙 = {
isEnd = 0
蛙 = {
isEnd = 0
种 = {
isEnd = 0
子 = {
isEnd = 1
}
}
草 = {
isEnd = 1
}
花 = {
isEnd = 1
}
}
}
皮 = {
isEnd = 0
卡 = {
isEnd = 0
丘 = {
isEnd = 1
}
}
丘 = {
isEnd = 1
}
}
代码实现
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<script type="text/javascript">
class DfaFilter {
constructor() {
this.trie = new Trie();
}
addWord(word) {
this.trie.insert(word);
}
filter(text) {
const result = [];
let i = 0;
while (i < text.length) {
const node = this.trie.search(text, i);
if (node) {
result.push({
start: i,
end: i + node.word.length,
word: node.word
});
i += node.word.length;
} else {
i++;
}
}
return result;
}
}
class Trie {
constructor() {
this.root = {
children: {},
word: null
};
}
insert(word) {
let node = this.root;
for (let i = 0; i < word.length; i++) {
const char = word[i];
if (!node.children[char]) {
node.children[char] = {
children: {},
word: null
};
}
node = node.children[char];
}
node.word = word;
}
search(text, start) {
let node = this.root;
for (let i = start; i < text.length; i++) {
const char = text[i];
if (!node.children[char]) {
return null;
}
node = node.children[char];
if (node.word !== null) {
return node;
}
}
return null;
}
}
// 使用示例
const filter = new DfaFilter();
filter.addWord("敏感词1");
filter.addWord("敏感词2");
filter.addWord("敏感词3");
const text = "这是一段包含敏感词1和敏感词3的文本。";
const result = filter.filter(text);
console.log(result);
// 输出: [
// { start: 7, end: 11, word: "敏感词1" },
// { start: 15, end: 19, word: "敏感词3" }
// ]
</script>
</body>
</html>
