

今天为大家分享一篇 58 同城大数据开发(流计算方向)社招的面经,附上答案。
面试方式通过项目来引出提问的知识点,主要考察面试人员对项目的理解能力以及背后涉及的原理。
面试时间:50 分钟
面试方向:大数据开发(流计算方向)
面试工具:微信视频面
面试难度 :⭐⭐⭐
面试环节
1 面试官:请简短的做个自我介绍。
面试官,您好!我叫 xxx , xxxx 年 x 月毕业于 xxx 学校,xx 学历,目前就职于 xxx 公司 xxx 部门,职位为:大数据开发工程师,主要从事于 Flink 流计算组件、平台的开发工作。
工作以来,我先后参加了 xxx 项目、xxx 项目以及 xxx 项目,积累了丰富的项目经验,同时,这 x 个项目都得到了领导的一致好评。
我对流计算组件有着浓厚的兴趣,工作之余经常钻研技术、例如:Flink 四大基石、Flink 内核应用提交流程、Flink 调度策略等。
入职 x 年,曾荣获优秀员工,以上是我的自我介绍,请面试官提问。
2 面试官:你做的这些项目主要是数据开发呢还是平台性质的?
主要面向平台,由于组内是研究 Flink 组件的,基于这个组件设计的平台,供公司多个部门使用。
3 面试官:那你介绍一下这三个项目,哪个是你最拿手的,并解决了哪些问题?
那我重点描述一下第三个项目,该平台对标阿里云的实时计算 Flink 平台。XXX 是一个 一站式、高性能的大数据处理平台,底层基于 Flink 实现,平台提供多种核心功能,支持多种 source、sink 插件,内置统一的元数据管理,支持 一键提交、应用管理、断掉调试、监控告警、Ranger 鉴权等多个核心模块。
我主要负责对该平台的 Flink 版本升级、从原先的 Flink 1.11.0 升级到 1.14.0,同时对平台进行架构重构及代码优化,并参与核心模块应用管理、Ranger 鉴权模块的开发工作。
主要解决了多部门提交 Flink 任务需要大量开关配置问题, 版本升级后的 SQL 语法校验、应用提交报错问题,以及 Ranger 鉴权问题。
4 面试官:应用提交都支持哪些方式?
支持 Flink SQL、Jar 包、画布 3 种方式。
5 面试官:使用 Jar 包提交支持哪些模式?
目前支持 Standalone、yarn 、K8s 三种方式,然后 通过 Yarn 提交时 支持 per job 模式,session 模式(专门少说了一种方式)
6 面试官:Flink on yarn 在新版本新增了一种模式,你知道吗?(果不其然,发问了)
知道,新增了 flink on yarn application 模式。该模式的最大特点是 原本在客户端需要做的事全部被提交到了 jobManager 中进行,也就是说 main()方法在集群中执行(入口点位于 ApplicationClusterEntryPoint ),客 户端只需要负责发起部署请求即可。
7 面试官:Flink on yarn application 设计的优点在哪?
首先 yarn-per-job 和 yarn-session 模式下,客户端都需要执行以下三步,即:
-
获取作业所需的依赖项; -
通过执行环境分析并取得逻辑计划,即 StreamGraph→JobGraph; -
将依赖项和 JobGraph 上传到集群中。
如下图简易版:
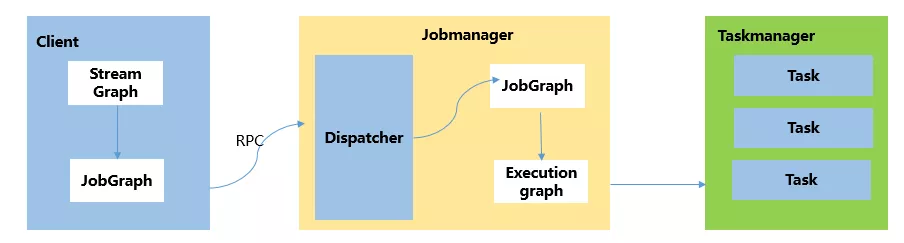
只有在这些都完成之后,才会通过 env.execute()方法 触发 Flink 运行时真正地开始执行作业。如果所有用户都在同一个客户端上提交作业,较大的依赖会消耗更多的带宽,而较复杂的作业逻辑翻译成 JobGraph 也需要吃掉更多的 CPU 和内存,客户端的资源反而会成为瓶颈。
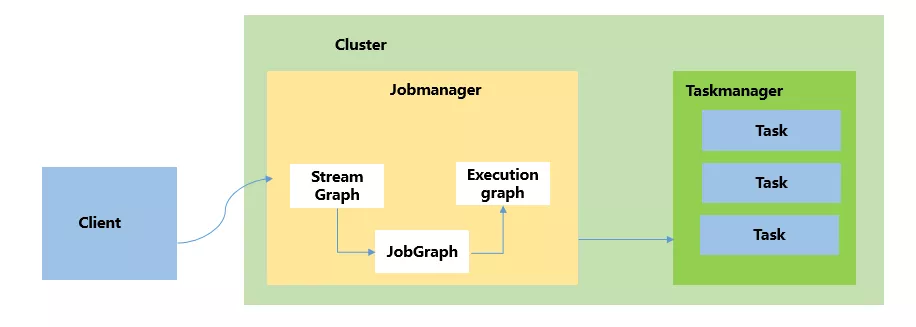
Application 模式。将原本需要在客户端做的三件事都被转移到了 JobManager 里,客户端只需要负责发起部署请求。大大减小了 客户端 CPU 和内存的使用资源。简易版原理图如下:
8 面试官:平台进行架构重构及代码优化,这块是如何设计的?
开发初期,使用人过少,且合作部门只有一个,只采用单接口设计、后期多部门合作时,之前设计的架构会导致每个部门都需要单独维护一个版本。
经过问题分析后,对之前的代码进行解构,其核心思想在于独立每个业务场景的 Web 上下文,通过 WebInstall 接口实现,让其他多部门实现其接口。
WebInstaller 里面定义了 3 个方法,分别为 inin(),run(),close(). init()负责初始化工作、如配置文件加载,数据库初始化等。run()负责启动,例如 Metric、Watchdog 等;close()负责 Web 服务关闭,会被作为关闭钩子函数(ShutdownHook)注册起来。
xxx 作为主类,会在运行时根据配置参数反射生成不同的 WebInstaller,从而实现在不同业务场景下运行其对应的 Web 服务,从根本上去掉了大量开关配置。
9 面试官:看你解决了 SQL 校验问题,Flink SQL 提交流程包含哪几步?
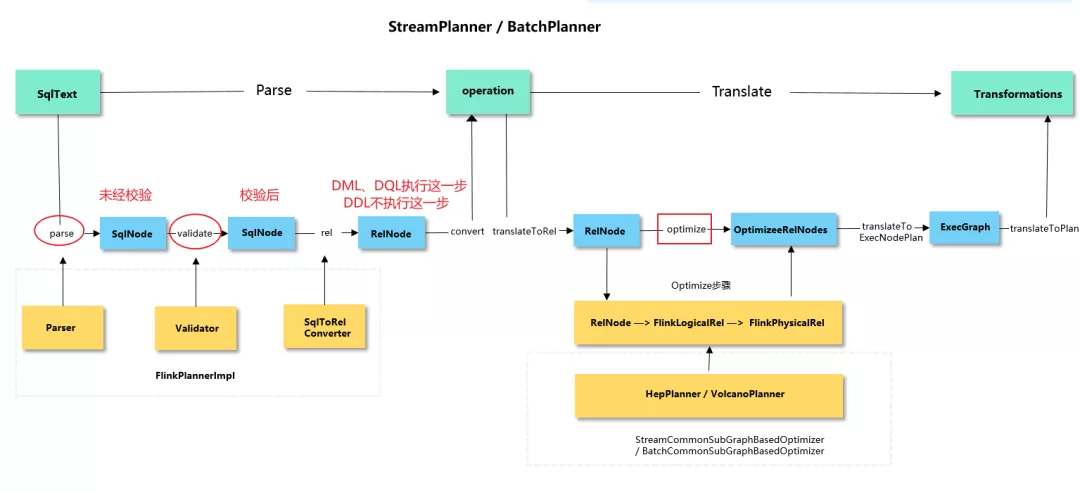
Flink sql 在被提交到集群之前都需要先被转换成 Transformations,然后编译成 StreamGraph,通过优化生成 JobGraph.
在被转为 Transformations 时主要涉及两大阶段:
-
SQL 语句到 Operation 的转换,即 Parse 阶段; -
Operation 到 Transformations 的转换,即 Translate 阶段。
在 Parse 阶段一共包含 parse、validate、rel、convert 四个部分。
在 Translate 阶段 一共包含 translateToRel、optimize、translateToExecNodeGraph 和 translateToPlan 四个阶段。
原理图如下:
10 面试官:在 SQL 校验环节做了哪些操作?
SQL 校验环节主要是对经过 parser 解析出的 AST 进行有效性验证,验证的方面主要包括两方面:
1 表名、字段名、函数名是否正确,如在某个查询的字段在当前SQL位置上是否存在或有歧义
2 特定类型操作自身的合法性.
11 面试官:Ranger 鉴权模块是干什么的?
我们的 xxx 作为一个流计算平台,提供给第三方时,要保证数据的安全性。
所以需要对用户提交的 SQL 基于 ranger 信息进行鉴权,确定其权限。
实现步骤:
鉴权主要有三大模块
1 逻辑计划解析:解析 xxx sql ,拦截执行计划.
2 flink-ranger 插件自研:将 flink sql 库、表、字段等操作信息,转换成 ranger 鉴权所需信息,完成鉴权。
3 ranger 策略同步:将 ranger 配置策略,同步到自研插件中。
具体的实现流程:
鉴权在 xxx 中主要分为 3个步骤:
1 用户在平台上 执行 sql ,通过 flink-planner 模块进行 sql 解析,并执行。
2 拦截 flink 源码中#executeOperation,获取 sql 操作的具体细节。
3 将 sql 按照 DDL\DML\DQL 等方式,分别包装为 ranger 鉴权信息,完成鉴权。
12 面试官:看你介绍时提到平台包含监控告警模块,是通过什么进行监控的,主要监控哪些指标?
通过 Flink Metrics 对指标进行监控。使用 Flink 提供的主动方式 PrometheusPushGatewayReporter 方式 通过 prometheus + pushgateway + grafana 组件搭建 Yarn 提交模式进行可视化监控
主要监控 (JM、TM、Slot、作业、算子)等相关指标。以及集群 CPU、内存、线程、JVM、网络等运行组件的指标。
13 面试官:Flink Metrics 提供了几种监控指标类型?分别是哪些?
Flink Metrics 一共提供了四种监控指标:分别为 Counter、Gauge、Histogram、Meter。
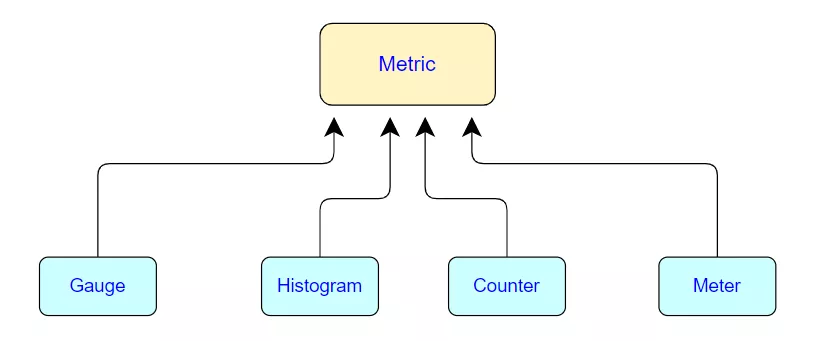
-
Count 计数器统计一个指标的总量 -
Gauge:反映一个指标的瞬时值。比如要看现在 TaskManager 的 JVM heap 内存用了多少,就可以每次实时的暴露一个 Gauge,Gauge 当前的值就是 heap 使用的量。 -
Meter:平均值,用来记录一个指标在某个时间段内的平均值。Flink 中的指标有 Task 算子中的 numRecordsInPerSecond,记录此 Task 或者算子每秒接收的记录数。 -
Histogram:直方图,用于统计一些数据的分布,比如说 Quantile、Mean、StdDev、Max、Min 等,其中最重要一个是统计算子的延迟。此项指标会记录数据处理的延迟信息,对任务监控起到很重要的作用。
14 面试官:我看你简历中写了对全链路吞吐、全链路时延、吞吐时延指标进行监控和调优,全链路时延是怎么计算的?
全链路时延指的是
一条数据进入 source 算子到数据预处理算子直到最后一个算子输出结果的耗时,即处理一条数据需要多长时间。包含算子内处理逻辑时间,算子间数据传递时间,缓冲区内等待时间。
全链路时延要使用 latency Marker 计算。latency Marker 是由 source 算子根据当前本地时间生成的一个 marker ,并不参与各个算子的逻辑计算,仅仅跟着数据往下游算子流动,每到达一个算子则算出当前本地时间戳并与 source 生成的时间戳相减,得到 source 算子到当前算子的耗时,当到达 sink 算子或者说最后一个算子时,算出当前本地时间戳与 source 算子生成的时间戳相减,即得到全链路时延。原理图如下:
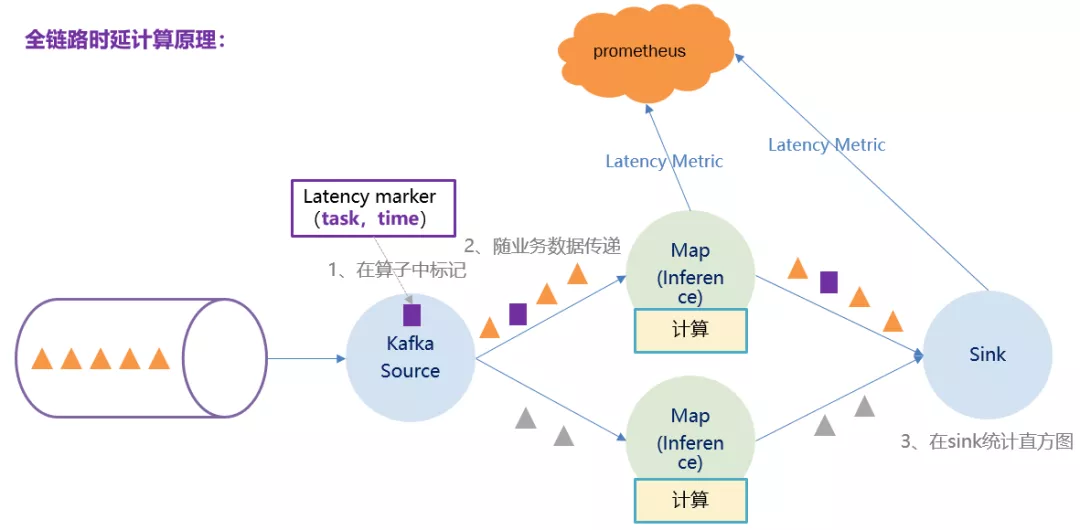
15 面试官:全链路时延计算公式怎么计算的?(重点)
计算公式:
avg(flink_taskmanager_job_latency_source_id_
operator_id _operator_subtask_index_latency{
source_id="cbc357ccb763df2852fee8c4fc7d55f2",
operator_id="c9c0ca46716e76f6b700eddf4366d243",quantile="0.999"})
16 面试官:怎么实现对吞吐的监控的?比如说怎么知道 source 端的吞吐量?
通过 Flink Metrics 的 Count 计数器,以及 Gauge 可以实现对 source 端吞吐量的监控
17 面试官:我们聊聊 Flink 的一些知识点,说一下 WaterMarker 机制
WaterMark 是用来解决数据延迟、数据乱序等问题。
水印就是一个时间戳(timestamp),Flink 可以给数据流添加水印
-
水印并不会影响原有 Eventtime 事件时间 -
当数据流添加水印后,会按照水印时间来触发窗口计算,也就是说 watermark 水印是用来触发窗口计算的 -
设置水印时间,会比事件时间小几秒钟,表示最大允许数据延迟达到多久
Flink 提供了常规的定期水位线以及定制化的标点水位线两种生成水位线的方式供用户选择。
(1) 定期水位线:周期性的生成 watermark,系统会周期性的将 watermark 插入到流中。默认周期是 200 毫秒。
(2) 标点水位线:没有时间周期规律,可打断的生成 watermark, 每一次分配 Timestamp 都会调用生成方法。
18 面试官:结合 kafka 说一下,flink 如何实现 exactly once 语义的?
Flink 使用两阶段提交协议 预提交(Pre-commit)阶段和 提交(Commit)阶段保证端到端严格一次。
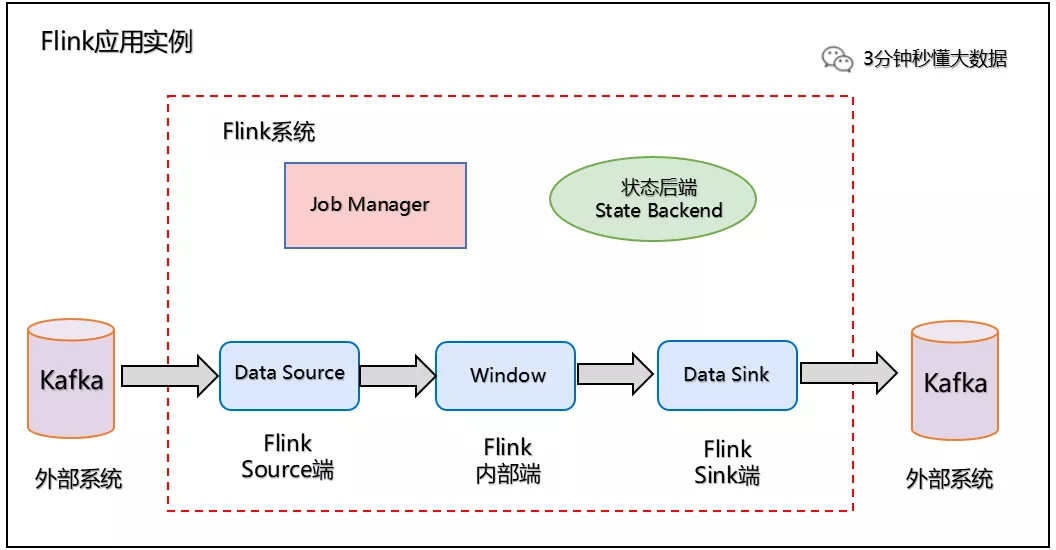
(1)预提交阶段
1、当 Checkpoint 启动时,进入预提交阶段,JobManager 向 Source Task 注入检查点分界线(CheckpointBarrier),Source Task 将 CheckpointBarrier 插入数据流,向下游广播开启本次快照,如下图所示:
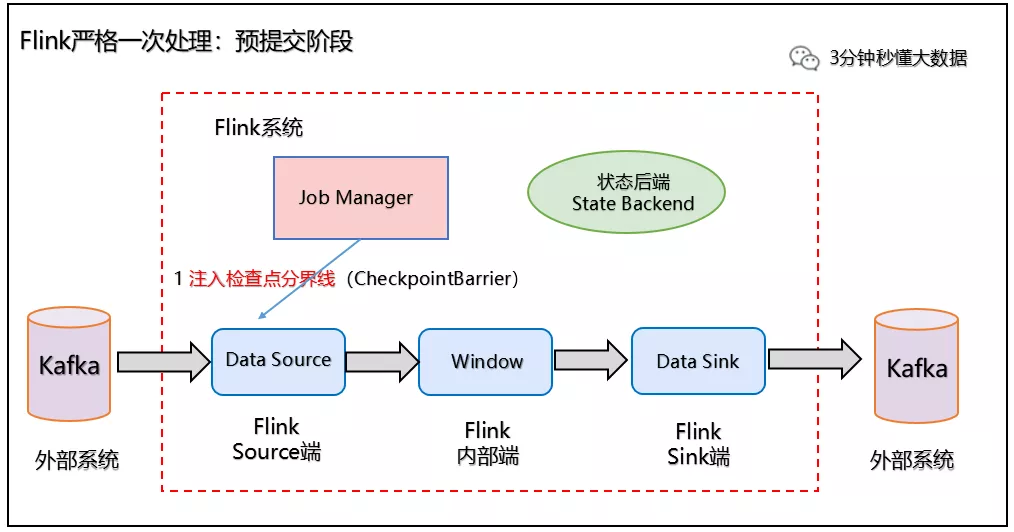
预处理阶段:Checkpoint 启动
2、Source 端:Flink Data Source 负责保存 KafkaTopic 的 offset 偏移量,当 Checkpoint 成功时 Flink 负责提交这些写入,否则就终止取消掉它们,当 Checkpoint 完成位移保存,它会将 checkpoint barrier(检查点分界线) 传给下一个 Operator,然后每个算子会对当前的状态做个快照,保存到状态后端(State Backend)。
对于 Source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 Checkpoint 恢复时,Source 任务可以重新提交偏移量,从上次保存的位置开始重新消费数据,如下图所示:
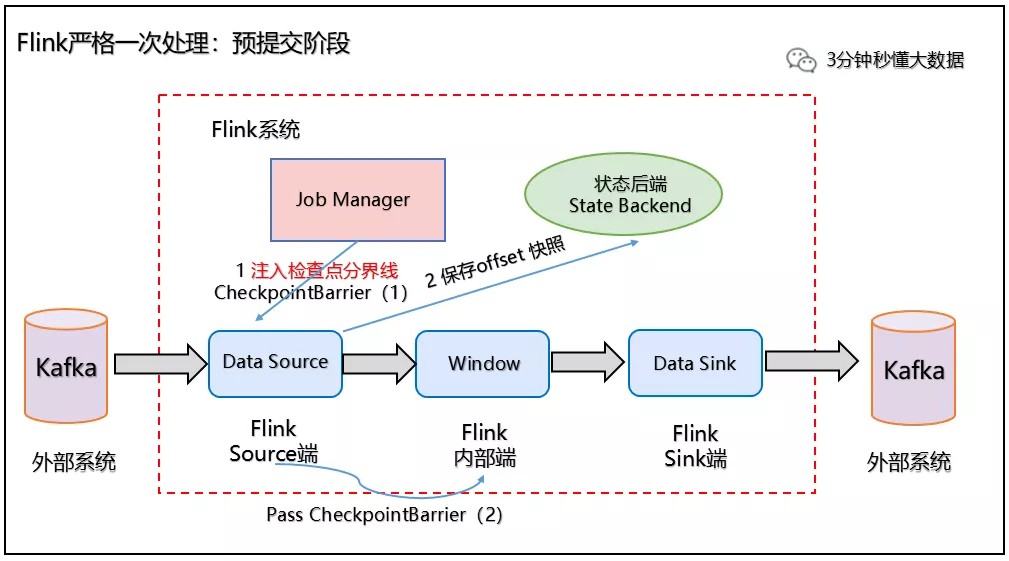
预处理阶段:checkpoint barrier 传递 及 offset 保存
3、Sink 端:从 Source 端开始,每个内部的 transformation 任务遇到 checkpoint barrier(检查点分界线)时,都会把状态存到 Checkpoint 里。数据处理完毕到 Sink 端时,Sink 任务首先把数据写入外部 Kafka,这些数据都属于预提交的事务(还不能被消费),此时的 Pre-commit 预提交阶段下 Data Sink 在保存状态到状态后端的同时还必须预提交它的外部事务,如下图所示:
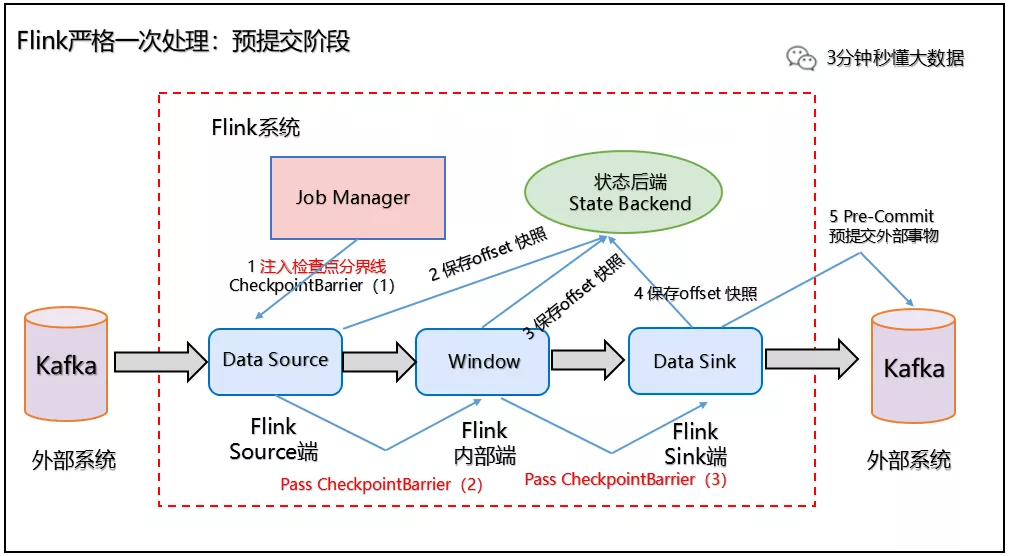
预处理阶段:预提交到外部系统
(2)提交阶段
4、当所有算子任务的快照完成(所有创建的快照都被视为是 Checkpoint 的一部分),也就是这次的 Checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 Checkpoint 完成,此时 Pre-commit 预提交阶段才算完成。才正式到两阶段提交协议的第二个阶段:commit 阶段。该阶段中 JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调逻辑。
所有算子 收到确认通知,就会正式提交之前的事务,Kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了。如下图所示:
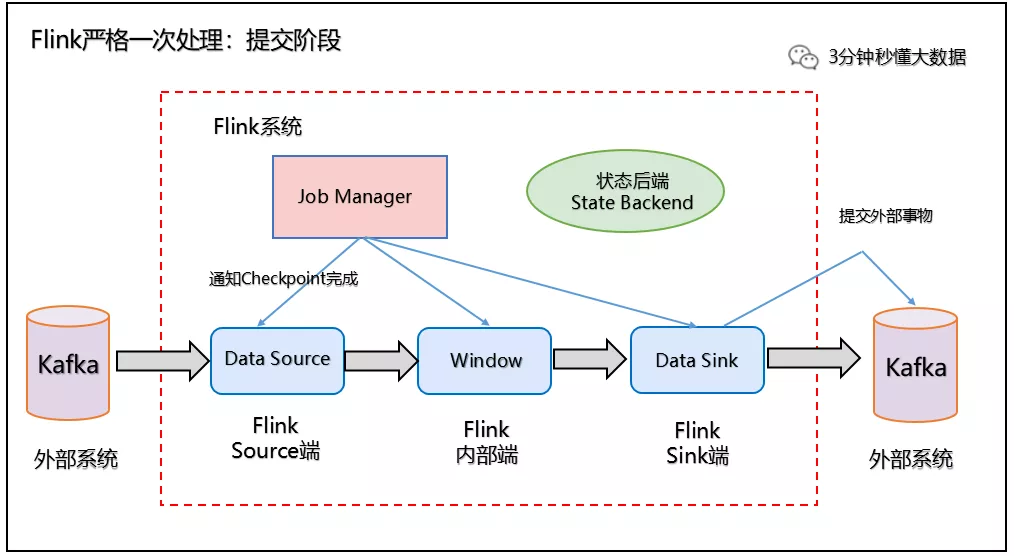
提交阶段:数据精准被消费
19 面试官:Flink HBase 支持 Exactly once 语义吗?
使用 hbase 的幂等性结合 at least Once(flink 中 state 能恢复,在两次 checkpoint 间可能会有重复读取数据的情况)实现精确一次性语义。
20 面试官:Flink HDFS 支持 Exactly once 语义吗?
支持,Flink 中 sink 数据到 HDFS 可以通过 BucketingSink 来完成。
21 面试官:好,我们问一些 kafka 方面的问题,先简单介绍一下 kafka的架构
Kafak 总体架构图中包含多个概念:如下图所示:
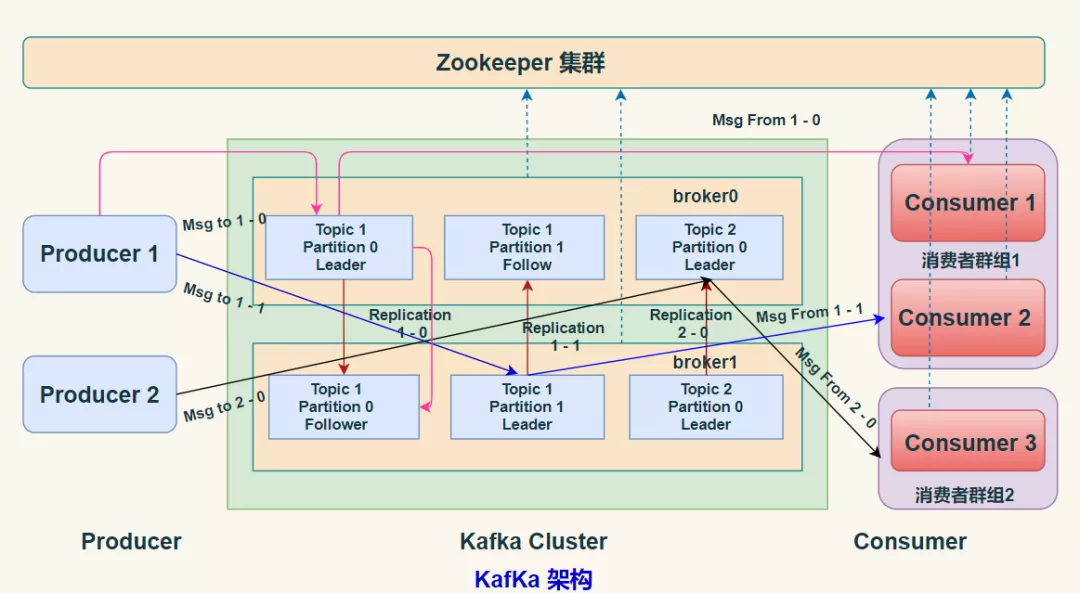
(1)ZooKeeper:Zookeeper 负责保存 broker 集群元数据,并对控制器进行选举等操作。
(2)Producer:生产者负责创建消息,将消息发送到 Broker。
(3)Broker: 一个独立的 Kafka 服务器被称作 broker,broker 负责接收来自生产者的消息,为消息设置偏移量,并将消息存储在磁盘。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
(4)Consumer:消费者负责从 Broker 订阅并消费消息。
(5)Consumer Group:Consumer Group 为消费者组,一个消费者组可以包含一个或多个 Consumer 。
使用 多分区 + 多消费者 方式可以极大 提高数据下游的处理速度,同一消费者组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消费消息时互不影响。Kafka 就是通过消费者组的方式来实现消息 P2P 模式和广播模式。
(6)Topic:Kafka 中的消息 以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。
(7)Partition:一个 Topic 可以细分为多个分区,每个分区只属于单个主题。同一个主题下不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的 日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的 偏移量(offset)。
(8)Offset:offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka保证的是分区有序性而不是主题有序性。
(9)Replication:副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有主副本对外提供读写服务,当主副本所在 broker 崩溃或发生网络异常,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。
(10)Record:实际写入 Kafka 中并可以被读取的消息记录。每个 record 包含了 key、value 和 timestamp。
(11)Leader: 每个分区多个副本的 “主” leader,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
(12)follower: 每个分区多个副本中的”从” follower,实时从 Leader 中同步数据,保持和 leader 数据的同步。Leader 发生故障时,某个 follow 会成为新的 leader。
22 面试官:kafka 如何做到高吞吐量和性能的?
kafka 在写方面通过页缓存技术、磁盘顺序写 实现写数据的超高性能,在读方面通过 零拷贝实现高吞吐和高性能的。
1、页缓存技术
Kafka 是基于 操作系统 的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做 page cache,是在 内存里的缓存,我们也可以称之为 os cache,意思就是操作系统自己管理的缓存。
Kafka 在写入磁盘文件的时候,可以直接写入这个 os cache 里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把 os cache 里的数据真的刷入磁盘文件中。通过这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,原理图如下:
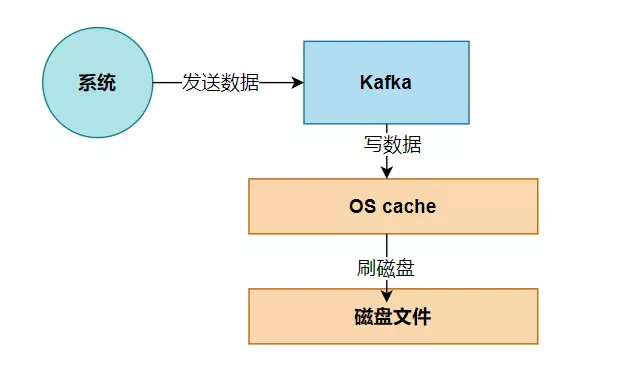
2、磁盘顺序写
另一个主要功能是 kafka 写数据的时候,是以磁盘顺序写的方式来写的。也就是说,仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据。
普通的机械磁盘如果你要是随机写的话,确实性能极差,也就是随便找到文件的某个位置来写数据。
但是如果你是 追加文件末尾 按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能相差无几。
基于上面两点,kafka 就实现了写入数据的超高性能。
3、零拷贝
从 Kafka 里消费数据的时候实际上就是要从 kafka 的磁盘文件里读取某条数据然后发送给下游的消费者,如下图所示。
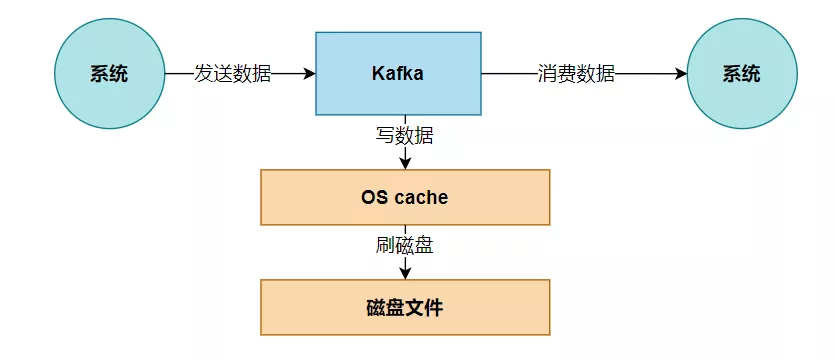
那么这里如果频繁的从磁盘读数据然后发给消费者,会增加两次没必要的拷贝,如下图:
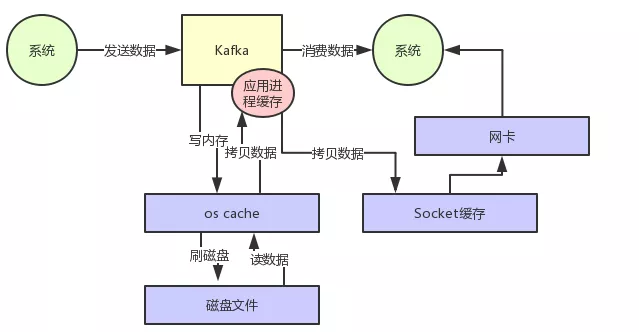
一次是从操作系统的 cache 里拷贝到应用进程的缓存里,接着又从应用程序缓存里拷贝回操作系统的 Socket 缓存里。
而且为了进行这两次拷贝,中间还发生了好几次上下文切换,一会儿是应用程序在执行,一会儿上下文切换到操作系统来执行。所以这种方式来读取数据是比较消耗性能的。
Kafka 为了解决这个问题,在读数据的时候是引入零拷贝技术。
也就是说,直接让操作系统的 cache 中的数据发送到网卡后传输给下游的消费者,中间跳过了两次拷贝数据的步骤,Socket 缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到 Socket 缓存,如下图所示:
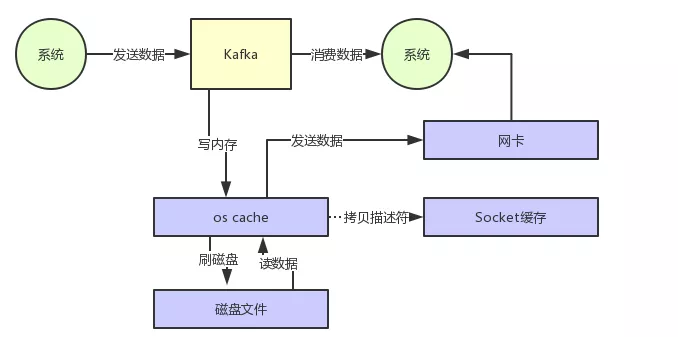
通过 零拷贝技术,就不需要把 os cache 里的数据拷贝到应用缓存,再从应用缓存拷贝到 Socket 缓存了,两次拷贝都省略了,所以叫做零拷贝。
对 Socket 缓存仅仅就是拷贝数据的描述符过去,然后数据就直接从 os cache 中发送到网卡上去了,这个过程大大的提升了数据消费时读取文件数据的性能。
Kafka 从磁盘读数据的时候,会先看看 os cache 内存中是否有,如果有的话,其实读数据都是直接读内存的。
kafka 集群经过良好的调优,数据直接写入 os cache 中,然后读数据的时候也是从 os cache 中读。相当于 Kafka 完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
23 面试官:说一下 kafka 的 ISR 机制?
在分区中,所有副本统称为 AR ,Leader 维护了一个动态的 in-sync replica(ISR),ISR 是指与 leader 副本保持同步状态的副本集合。当然
leader 副本本身也是这个集合中的一员。当 ISR 中的 follower 完成数据同步之后,
leader就会给 follower 发送ack,如果其中一个 follower 长时间未向 leader 同步数据,该 follower 将会被踢出 ISR 集合,该时间阈值由replica.log.time.max.ms参数设定。当 leader 发生故障后,就会从 ISR 集合中重新选举出新的 leader。
24 面试官:如果数据量过大,kafka 会怎么处理?
首先,数据量过大,会造成 1 broker 压力大,2 磁盘压力大,3 消费者压力大,4 log 变大.
这时候需要做的就是,1.扩充 broker,2.挂载多个磁盘,3. 增加消费者,增大消费能力,4 扩分区提升并行能力,5 增大消息批次大小,减少网络请求压力
25 面试官:问一些 java 方面的知识点吧,JVM 内存划分了解吗?
Java 虚拟机在执行 Java 程序的过程中会把它在主存中管理的内存部分划分成5个区域:
1.程序计数器,2.Java 虚拟机栈,3.本地方法栈、4.方法区、5.Java 堆。
其中 程序计数器,Java 虚拟机栈,本地方法栈线程私有,方法区、Java 堆线程共享。对象一般在堆中生成,垃圾回收也在这里发生。
26 说一个算法的实现思路吧。快速排序的实现思路可以简单说一下吗?
快速排序的基本思想:挖坑填数+分治法。
它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序使用分治策略来把一个序列(list)分为两个子序列(sub-lists)。步骤为:
-
从数列中挑出一个元素,称为”基准”(pivot)。 -
重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。 -
递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
时间复杂度:O(nlog2n)
27 面试官:好的,我这边暂时就这么多问题啦,你有什么想问的吗?
1 部门主要工作,2 近 1-2 年的规划,3 多久会有下一面通知。

